More about the StoryEngine methodology, as well as guidance and documentation on how to get started, is available as a GitBook. (It’s a bit out of date but the basics are there.)
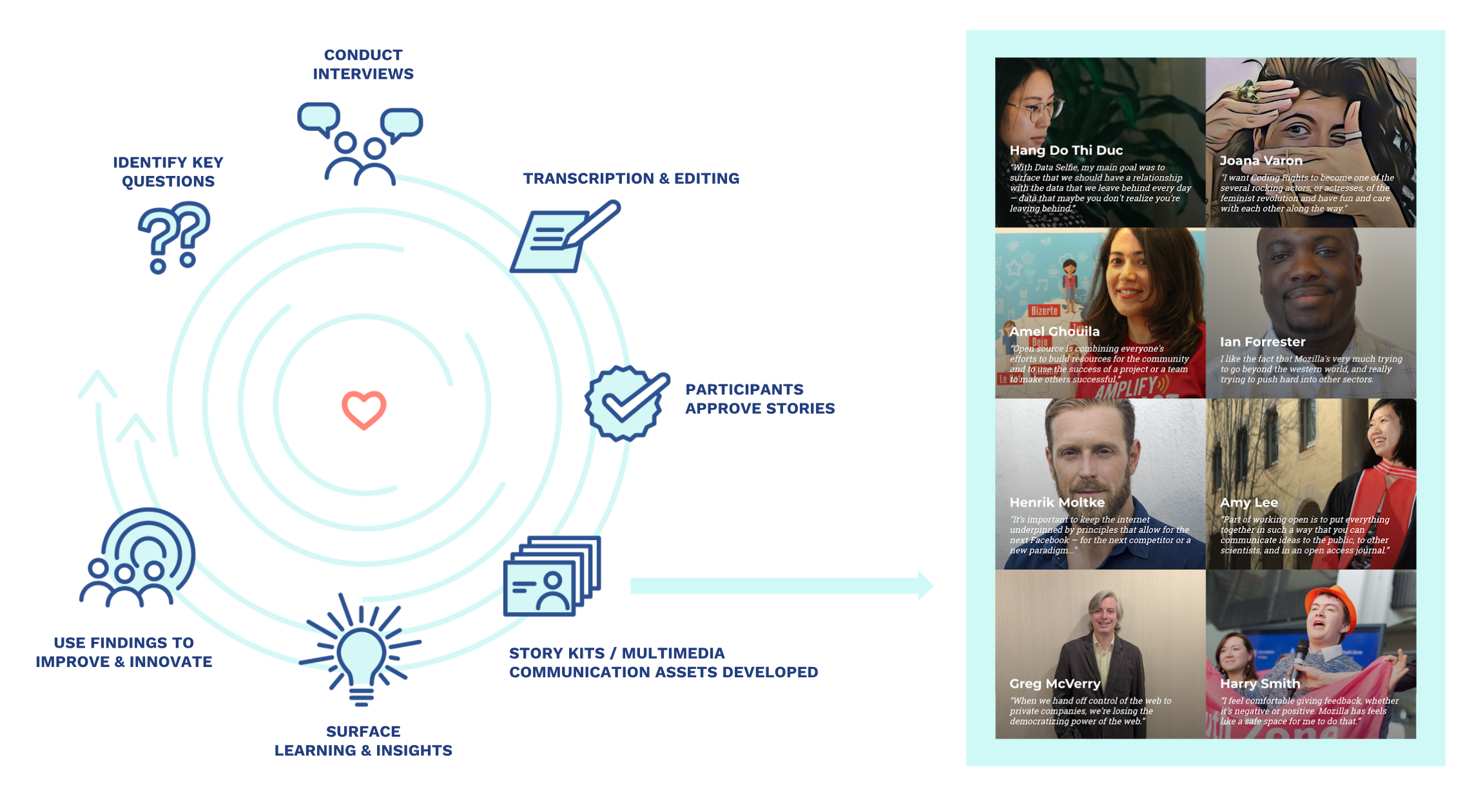
More about the StoryEngine methodology, as well as guidance and documentation on how to get started, is available as a GitBook. (It’s a bit out of date but the basics are there.)